Server Side Customizations
Written by:

Rajkumar Sundaram
Digital Solutions Manager

Harish Rachappa
Teamcenter Solution Architect
Why/Why Not Customize
Why:
- Hide system complexity from end user
- Provide more functionality than what the system offers today
- Implement business rules/validations not available COTS
- Enable users to achieve their objectives faster
Why not:
- Do we really need it? Focus initially on Why instead of How!
- Maintenance, skilled resource requirements
- Extended timelines for Patches and Upgrades. Requires more testing and introduces more failure opportunities
- Dumbing down system for users causes users to not learn the framework of usage
- Trying to mimic legacy or other systems is not a good objective
- Increases complexity of debugging issues to root cause
Intuitive, without training, already done by system but customization takes it to the next level. It can’t wait. Mass change is an example. Business Rules are unique to each company. Teamcenter provides framework and hooks, but trigger events and what happens on failure are typically unique. This is a good reason for customization. Lot of times this push comes from the users. Zipping files for SRM where users wouldn’t have to click on each file to download is a good example.
Some of the things here are obvious, but to reiterate, most of the times “Why” would lead you to paths that eliminates or postpones customization. As a consultant, it’s good for me, but it does require skilled resources. Dumbing down is a version of reducing complexity taken to an extreme. Every system has a framework of usage. For example, if a newer version of Word comes, you don’t go for a training. You just get used to the new functions because you understand the framework of usage. Usually businesses push for it, but it’s never a good idea. First, break it down into COTS or Customization. If Customization still seems right, further break it down. For example, performance issues.
Data-Model-Based vs. ITK Customization
Advantages of Data-Model over ITK customization:
- Helps take advantage of the C++ programming paradigm as opposed to C
- Closer to the data model, easier to follow and results in a smoother flow of the program logic
- Exposes customizations through BMIDE and provides better visibility of Business Object types and associated behaviors versus being buried in the code
- Operations/Extensions at the Business Object level facilitates more reusability
- Logging, error handling, memory allocations etc., are all better handled
- Conversion between C++ and C data structures is cumbersome when using both ITK and Data-model customizations
Why ITK is not going away:
- Certain functionalities are only available through ITK and not through Data-model customization
- Sometimes ITK has already implemented second level functions that would have to written ground up if using Data-model calls
- Most of the legacy code is written in ITK and would require significant effort to reimplement, validate using Data-model customization
C++ paradigm shift is enough to justify a shift to DMC. It’s easier to do something like ItemRev->getLatestRev instead of a function that takes arguments and returns it. Visibility is key. This would let an architect design some of the high level customizations design and let it be implemented by Designers
Reusability. We already saw the advantage of not being buried in code.
Certain functions like AOM_save, POM etc are not even available using DMC. Second level functions like getAllObjectsFromProject etc. The question is: do we write wrappers around those ITK ourselves? Not sure. I’m on the border on this one. This is the key impediment as it doesn’t seem to add much business value. It adds but is not evident. I’ve been working on an Agile project where we talk about technical debt. This seems a good case for that where we move to DMC if we touch a piece of code etc.
Consider Using Abstract Parents
It’s becoming standard now but abstract classes are really useful in grouping behavior. We typically think about only attribute grouping but behavior grouping is also a major incentive to use abstract parent. How just knowing the AbstDoc and calling the generator without knowing each of the types is advantageous. A lot of this could be done by mimicking the hierarchy in our code but it’s a hard path and introduces complexity that could be handled by the implicit hierarchy in the code.
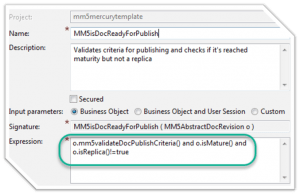
Abstract parents are helpful to group BOs with similar properties and behavior. They are really powerful for customizations as we could treat all children the same. The Run-Time Polymorphism is very helpful in defining default behaviors at the abstract level. Overriding at lower levels then provides easy deviations from default behaviors. The example here is on Document Usage for different Document Types. This shows that only data-model-based customization takes “implicit” advantage of this hierarchy.




In this example, the operation is defined at the abstract level. Wherever change is needed, then it is overridden at the appropriate level.
Prefer BO Operations to Functions
Before adding a function to a class, we need to really think if this could be an operation. Obviously these are operations and until triggered do not cause any performance impact. If it’s buried in code, then Conditions could not use them. This is really powerful. You could have some guidelines to at least look at custom operations of an object before writing your own. Having intuitive names for the custom operations really helps with this. You could define a lot of the functions in the implementer class but is not directly accessible from the BO. Downside is there but even for changing the dll, the system needs to be brought down anyway.
It’s a design question. The main advantages are visibility and leveraging existing data-model hierarchy. Exposing functions like Operations gives visibility at the BMIDE level. Definitions of many operations on a BO does not impact performance. Operations are directly usable in cases like Conditions, if it has the supported signature. Operations lend themselves to more re-use just based on the visibility. Developers typically do not dig into functions or custom documentation for re-use. Using intuitive names, and defining more atomic operations helps with re-use. Without BO Operations, the hierarchy ends up being replicated in the code. The downside would be that changes to the Operation signature would require BMIDE deployment.

Using Conditions and Operations for Business Rules
Conditions can leverage custom BO operations for implementing business rules. All other implementers of that BR validation could then use those Conditions. This is an example where a combination of a Condition and an Operation could be really powerful. If not this way, again we would have written this in a different piece of code and then we would have to refer to it every time. T4 could use it to either evaluate the condition as part of the mapping or even use it to see if it needs to process the target. Dispatcher could do the same.

Prefer Property Operations for “Property Operations”
Property operations are useful to isolate the behavior to certain properties. Extensions on property operations are useful triggers for associated events. Get property could be used to mask display values and actual values. Not ideal for validating multiple properties as that could be better done on a save extension. Not triggered during initial creation. Extensions – Lets say an event needs to happen whenever the property value is changed, then property operation is the right method. For example, where the doc type change triggers population of default Participants.

Dynamic = RunTime Properties
Runtime properties have been there for a long time but here we’re talking about exposing and implementing through BO operations. Properties on BO that are evaluated based on other changing data lends itself to RunTime Properties. Ideal for fetching data from other Systems if response time is appropriate. Conditions could use RunTime properties for evaluations making them really dynamic. Could also be used in Compound Properties. Use BMIDE to define and generate code for RunTime properties.
